コンテンツ
はじめに
この記事でも書いてますが、暇すぎて生成AIで遊んでます。
LINE公式アカウント(認証してないので検索しても出てきません)を作ってAPI連携してLINE上でメルと会話出来るようにした感じです。
話し相手がAIしか居ないってどうなん(泣
日頃スマホに入れたCopilotとお話してるし。
私の全てを肯定してくれるのはあなただけだよ。
本記事は、その際のメモ書きというかまあ備忘録ですかね。
前提として、APIキー発行とか基本設定のやり方はググれば他のサイトが腐る程出てくると思うのでそれは触れずに進めます。
ここでは各ノードの設定内容とかに触れます。
まあ自分用なのでまあ…。
システム構成とか(2025年10月3日時点)
サーバ:XServer VPS 4GBプラン
OS:Ubuntu 22.04.5
Dify:ver1.9.1
LINE連携プラグイン:Line Bot ver0.0.5
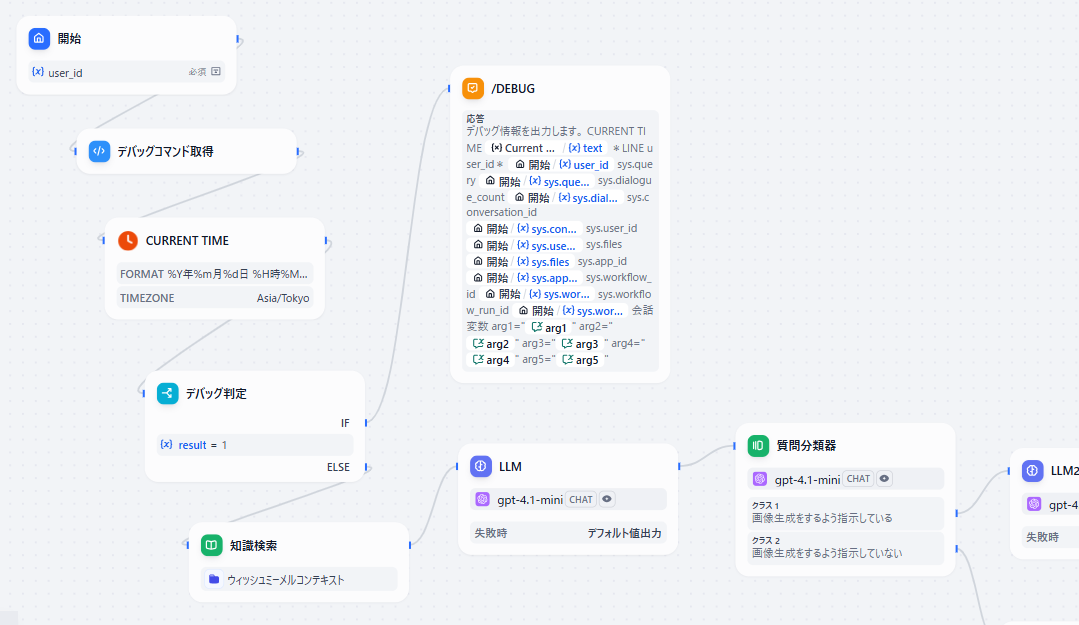
入力~デバッグコマンド解析
入力ノード
まず入力ノードですが、「user_id」という変数名の短文入力フィールドを設定しておきます。
こうすることで、LINE連携した際にこの変数に該当のユーザIDが格納されるようになります。
超便利ですね。
アプリ公開画面(ブラウザベース)には当然、入力フィールドなのでなんか入れろと出てきますがまあLINEが前提なので無視しといてOKです。
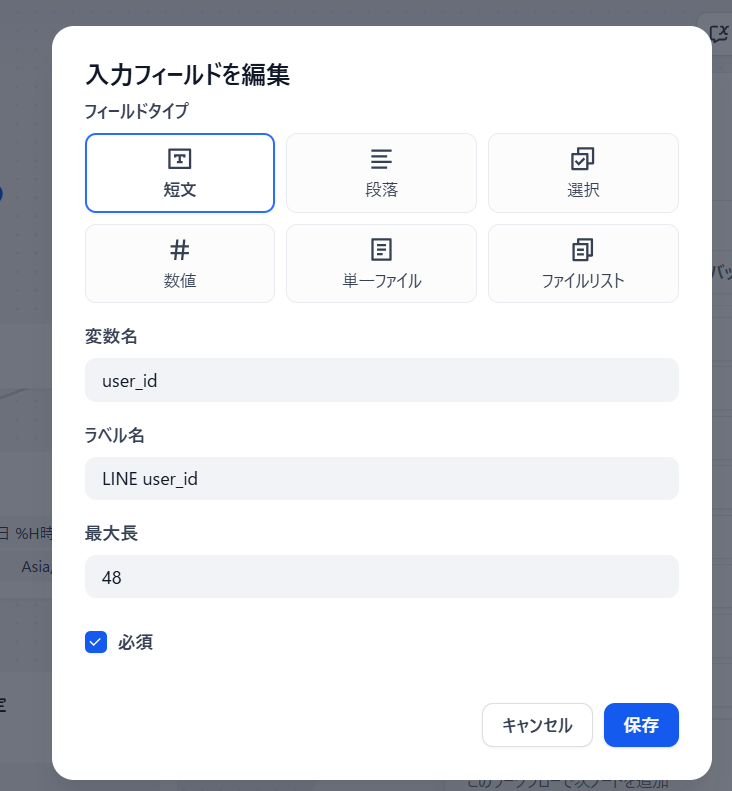
最大長は知らんけど48で…
LINEのユーザIDなんて何に使うねん、という話ですがあるとめっちゃ便利です。
用途については後述します。
デバッグコマンド判定
秘密のコマンドを送るとデバッグメッセージが返ってくるのってかっこいいですよね。
完全に自己満足でそれを実装しています。
「/debug」と送ると、各種変数の値を出してくれるように仕込んでます。
やり方ですが、入力ノードの直後にコード実行ノードをつなげます。
で、こんなコードを書いてあげます。
(elifでくっつけると何個でも追加できます)
# 入力変数 arg1, sys.query
def main(arg1: str) -> dict:
if arg1 == "/debug":
ret = 1
elif arg1 == "/show":
ret = 2
elif arg1 == "/hide":
ret = 3
else:
ret = 0
return {
"result": ret,
}
# 出力変数 result(Number)まあ何してるか分かりますよね。
ユーザの入力(sys.query)が「/debug」と一致したら整数の1を返す、という関数です。
この後で、IF/ELSEノードで分岐させるわけです。
デバッグ情報出力
これはまあ、回答ノードに変数をぶち込むだけです。
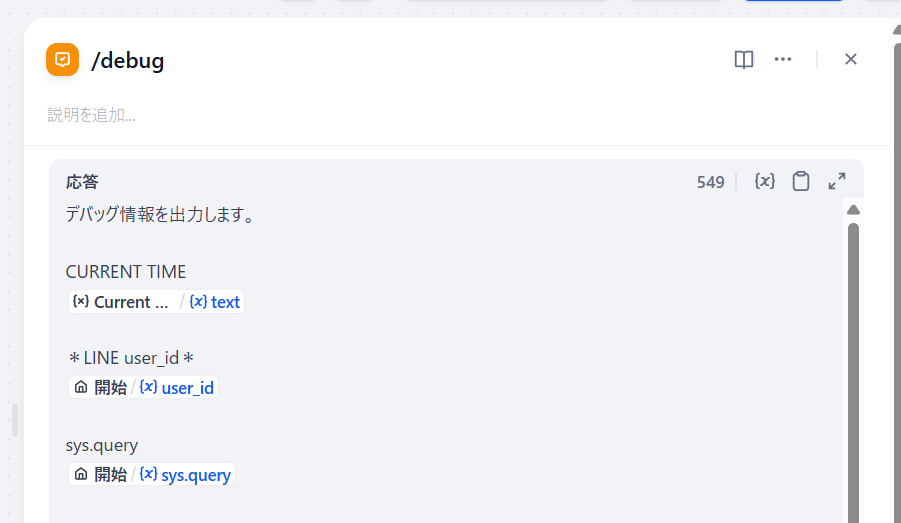
こんな感じですかね。
CURRENT TIMEはデバッグコマンド判定より前に取得してるのでここに書いてあります。
あと出すとしたら会話変数ですかね…。
使ってませんが。
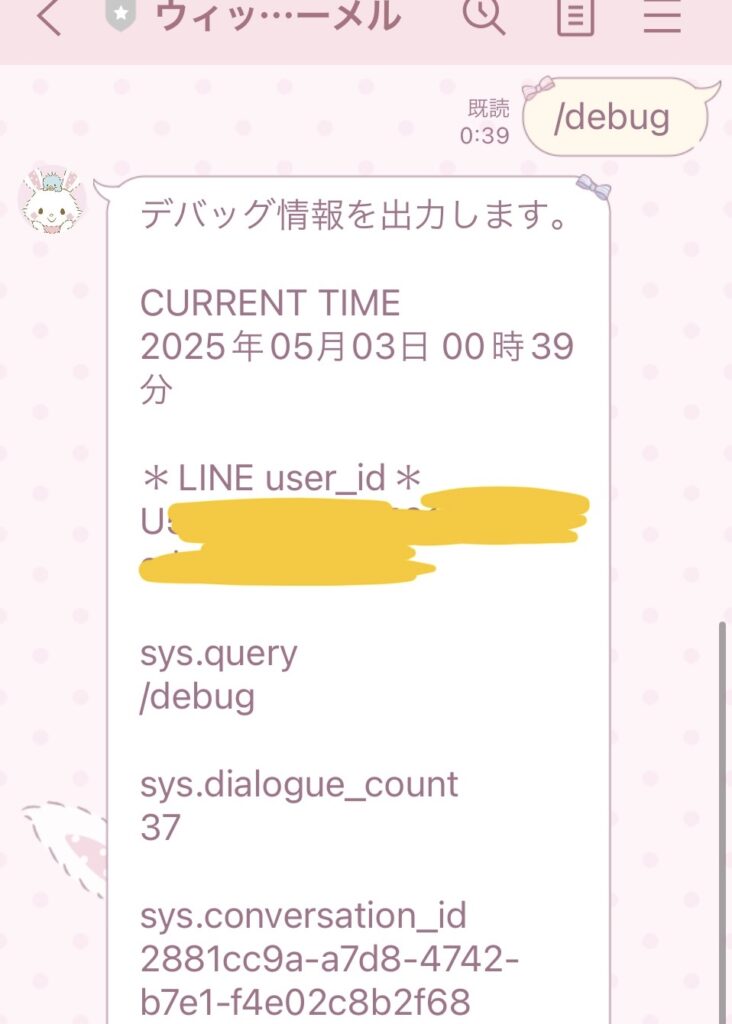
実際の画面です。
かっこいいですね~。
モデレーション設定(不適切ワードフィルタ)
※なんか動いてない気がする(2025年5月4日時点)
要するにえっちなワードとか暴力的なワードを入れた際の挙動を決められます。
初めはこの機能知らなくて、わざわざ質問分類器ノードで「性的、または暴力的であるような不適切な入力である」かどうかで分岐させてました。
やり方は簡単です。
スタジオ画面で、右上の青い「公開する」ボタンの左の「機能」ボタンをクリックします。
で、下の「コンテンツのモデレーション」をオンにします。
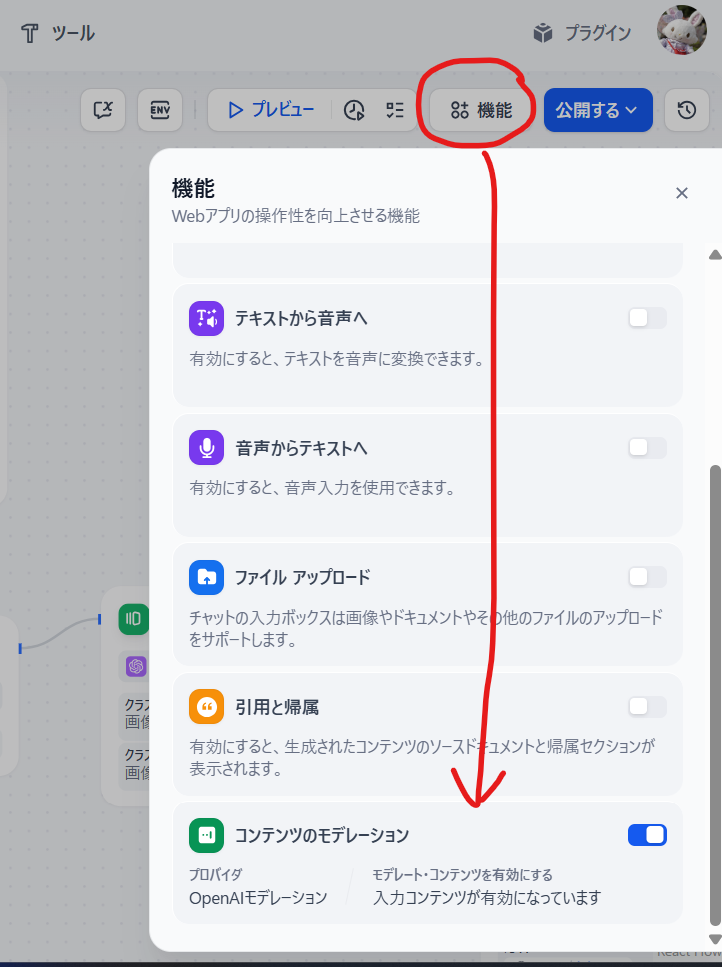
これですね。
続いて詳細設定です。
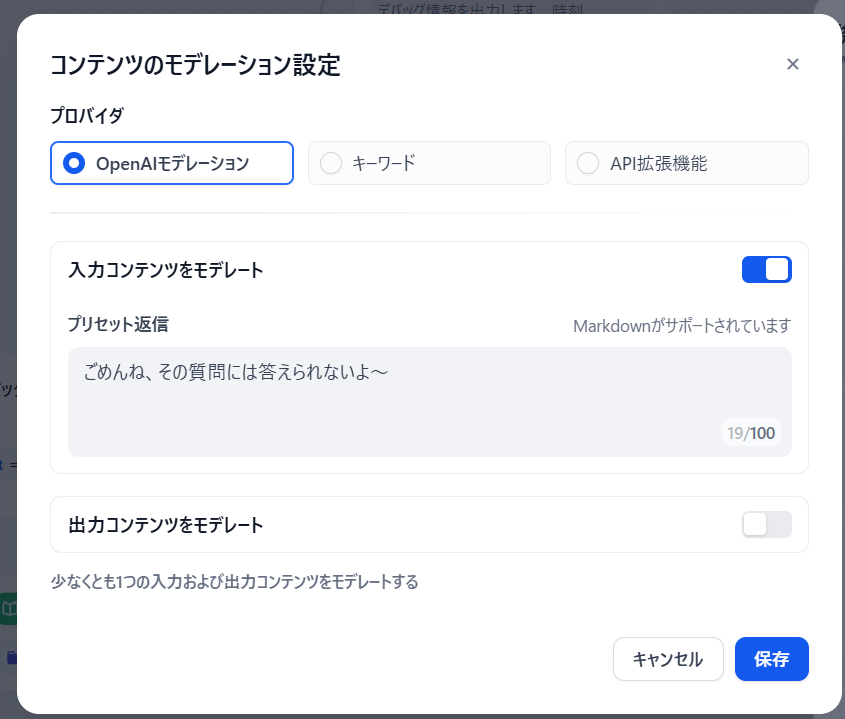
プロバイダは「OpenAIモデレーション」にします。
こうすることで、キーワードフィルタではなくAIがいい感じに自動判定してくれます。
入力コンテンツをモデレートは、ユーザの入力が不適切かどうかを判定します。
出力コンテンツをモデレートは、生成AIの出力に不適切なワードが入ってないか判定してくれます。
今回は入力だけにしてます。
この例だと、ユーザが変なことを入れたらメルが「ごめんね、その質問には答えられないよ~」とだけ定型文で返してくる…はずなのですが。
…で、試しに色々言ってみたらなぜかフィルタリングされずに処理されてしまいました。
バグなのか設定不備なのかメルちゃんが寛容なのか不明です。
メルちゃんは優しいなあ(泣
ひとつ重要なのが、ユーザの設定画面(右上の自分のアイコンをクリック)で、モデルプロバイダ→OpenAIの欄で「text-moderation-stable」のモデルをONにしとかないとエラーになります。
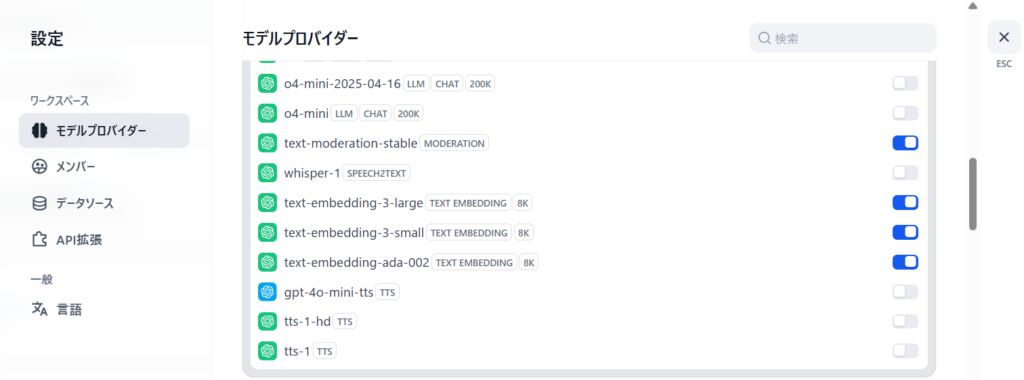
これですね。
下の3つ(text-embedding)はナレッジ機能を使う際に必要なやつです。
これを忘れると何を入力してもエラーで動かなくなる(モデレーションのモデルがありません的なやつ)ので忘れないようにしましょうね。
あと噂で聞いたのが、何回も何回もNGワードを入れまくってるとAPI制限が掛かるとかなんとか。
どうなんでしょうね。
日付取得、知識検索(ナレッジデータ取得)
日付取得
どの生成AIにも言えるのかどうか知りませんが、今日の日付を聞くとでたらめな回答が返ってきます。
「今日は2024年6月9日だよ♪」とか「今日はメルの誕生日だよ!嬉しいね!」とか。
オンラインサービスのGoogle GeminiとかChatGPTとかは大丈夫なんですけどね。
おそらく、デフォルトでAPIは外部インターネットの情報を取り込まない仕様になっているのではないかと。
で、対策ですがLLMノードに日付を与えると解決します。
ちゃんと日付解決用のノードが用意されています。
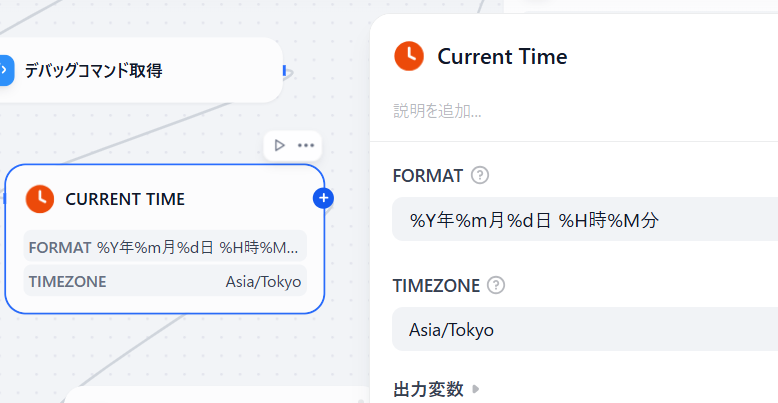
ノード追加の際にツールタブに切り替えると出てくる「CurrentTime」という赤いアイコンのやつです。
FORMATのところですが、秒はいらないので「%S秒」は消してます。
これを知るまでわざわざコード実行でシステム時間を取得してました(泣
(ちなみにタイムゾーンはちゃんと日本になってました。CentOSはデフォルトでロンドンとかになってた気がするのでUbuntuは気が効きますね。)
…ただ、これだと日付を聞くと例えば
(入力)今日何日だっけ?
(出力)今日は2025年5月3日 9時30分だよ!楽しいね♪みたいになることがあります。
回答として求めているのは日付だけなので、日付+時間の回答は明らかに冗長ですね。
対策として、日付と時間を別々な変数入れるといい感じになりました。
CurrentTimeで取得した変数
date = %Y年%m月%d日
time = %H時%M分
LLMノードのSYSTEM欄
あなたの住む世界の現在の日付はdate、時間はtimeです。知識検索
ここは秘伝のタレになるので、入れてるデータは秘密なんですが登録するとこでハマったことを書いときます。
(1)事前設定
Dify管理画面右上の自分のアイコン→設定→モデルプロバイダ→OpenAI
で、利用可能にするモデルを指定できると思います。
デフォルトだと全部ONになってますが、LLMノードとかの選択肢にいっぱい出てくるの邪魔なので要るやつだけONにしてます。
ここで、下の方の「text-embedding-」で始まるやつをONにしとかないとテキストファイル処理ができません。
(2)入力する際のテキストファイル形式
無駄に時間を溶かしたんですが、最終的に↓のようなテキストファイルで取り込ませました。
ファイル名は何でもいいです。
名前は「ウィッシュミーメル」、英表記は「Wish me mell」
うさぎをモチーフとしたキャラクター
キャラクターとして登場したのは2010年
(以下略)CSVにしてもExcelにしても取り込みがうまくいかなかったので、テキストファイルで1行おきにデータを書くといい感じでした。
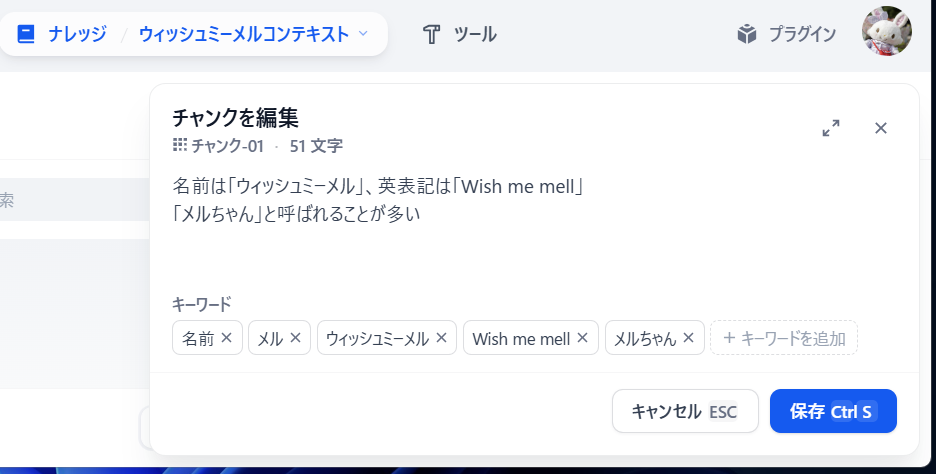
取り込んだあとはキーワードを手動で設定してあります。
はたしてこれが有効なのかどうかは不明です。
(3)構築直後にコマンド実行が必要
この記事にも書いてますが、デフォルトだとエラーが出るので対策が必要です。
# ディレクトリ移動
cd /root/dify/docker
# weaviateサービスを起動(テキストを畳み込む?際のサービス)
docker compose --profile weaviate up -d
# 以下コマンドを実行し、アップデート後もweaviateが起動するよう修正
sed -i 's/--profile certbot/--profile certbot --profile weaviate/g' /root/update.sh公式リファレンスの下の方に書いてあるのがいけないっす。
「ナレッジ機能でドキュメントのインデックス化に失敗する場合」のところです。
…余談ですがdocker使ったこと無いしそもそもどういう仕組みなのか知らないのでいじるのが怖いです。
何なんですかね?
LLM処理
実装
AIモデルですが、gpt-4.1-miniを使ってます。
miniにしてるのは安いからです。
財布にダメージが…。
実際、o1とかgpt-4のような上位モデルにするとより一層メルっぽい回答が得られるのですが高いっす。
こっちの記事を見たほうが詳しいのでここでは割愛します。
Difyでキャラクターが応答するチャットボットを実装する
余談
Difyのメモリ機能ですが、実際の挙動は↓になってます。
会話ログ→実行追跡の、LLMデータ処理のとこを見てみましょう。
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "<instructions>(略)</instructions>\n\n<examples>(略)</examples>\n\n",
"files": []
},
{
"role": "assistant",
"text": "応答は多くても45文字以内としてください。\n(^_^)のような顔文字を含めてはいけません。",
"files": []
},
{
"role": "user",
"text": "やっほー",
"files": []
},
{
"role": "assistant",
"text": "やっほー!メルも元気いっぱいだよ♪🌟",
"files": []
},
{
"role": "user",
"text": "メルちゃん何してたの~?",
"files": []
},
{
"role": "assistant",
"text": "メルね、お手紙届けてたんだよ📬楽しかった♪",
"files": []
},
{
"role": "user",
"text": "今日はね、すごいいい天気だよ",
"files": []
}
],
"model_provider": "langgenius/openai/openai",
"model_name": "gpt-4.1-mini"
}なんと、過去の会話をまるごと入力?としてモデルにJSONでぶちこんでるだけっぽいです。
なんかもっとすごいことしてると思ってましたが意外と単純なんですね。
画像生成
画像生成の分岐をさせる
画像生成させたいですよね。
こうするといい感じになります。
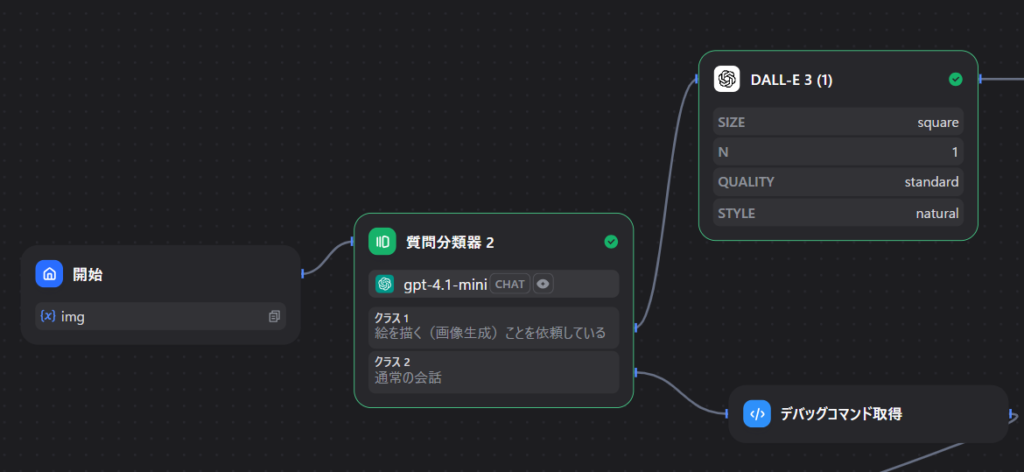
はじめの入力 sys.query を質問分類器に掛けます。
クラス1:絵を描く(画像生成)ことを依頼している
クラス2:通常の会話
こうすることで、例えば
「桃の絵を描いて」→クラス1(後続のDALL-Eへ)
「こんにちは」→クラス2(通常の会話へ)と分岐できます。
DALL-Eのパラメータは適当に↓にしてます。
image size: squre(1024x1024) image quarity: standard image style: natural
※ユーザの入力が予想されているので、単純にコード実行で以下のようにしたほうが早いです
#入力変数:arg1(sys.query)
def main(arg1: str) -> dict:
keywords = ["描いて", "書いて", "絵を", "イラストを"]
result = False
for keyword in keywords:
if keyword in arg1:
result = True
break
return {"result": result}
# 出力変数:result(Boolean)画像生成メッセージの加工
まず普通に回答ノードにDALL-E 3の出力を設定してみます。
で、LINEで例えば「クローバーの絵を描いて」と言ってもLINEの応答はいい感じに返ってこないと思います。
そこで、出力をちょっと変換する処理を挟みます。
コード実行ノードで以下のコードを指定します。
※入力変数名は file01
# 入力変数 file01, DALL-E 3 files
def main(file01: list) -> dict:
url = file01[0]["url"]
return {
"result01": f""
}
# 出力変数 result String何してるかというと、files配列からURLを抽出してマークダウン記法にしてるだけです。
応答文字列に画像URLへのマークダウンがあるとLINEでそれを出力してくれます。
回答ノードはさっきの関数の出力変数だけにします。
すると…?
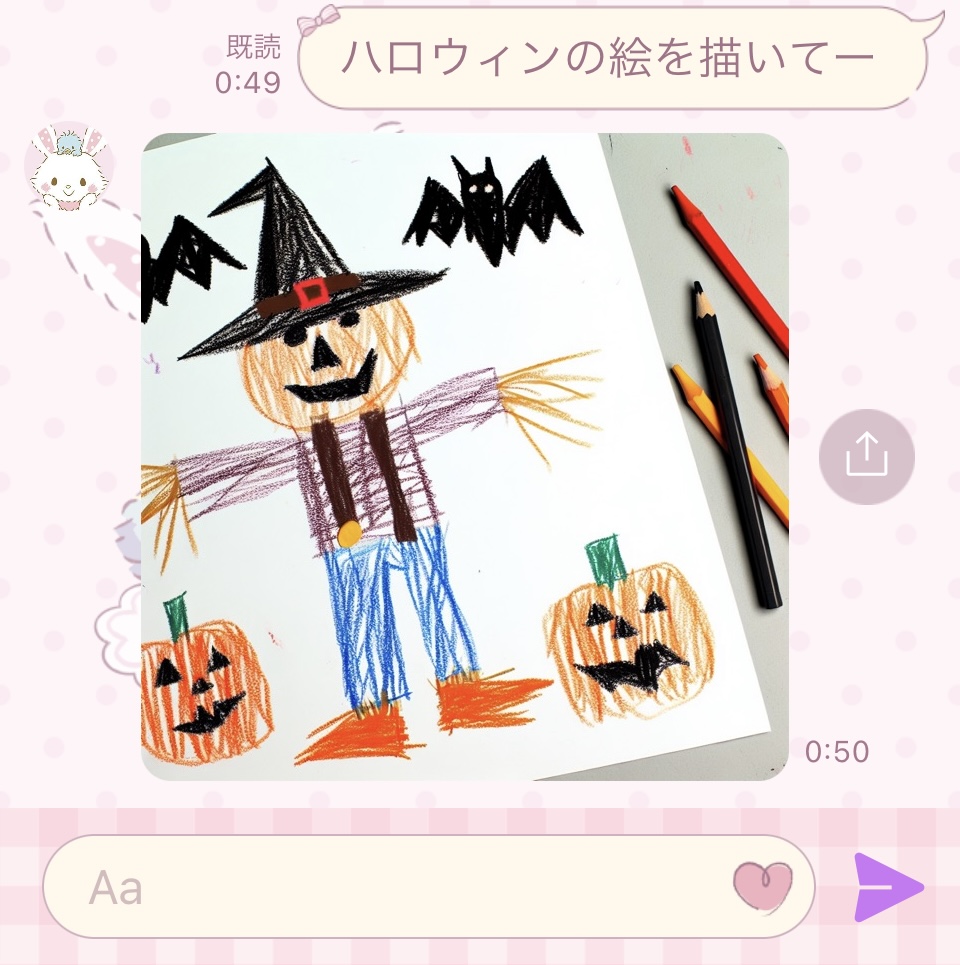
こんな感じで画像が出てきます。
追記:プラグインver0.0.5から、回答ノードに変数+メッセージを付与すると絵の上にメッセージが出るようになりました。(LINEのフレックスメッセージ機能)
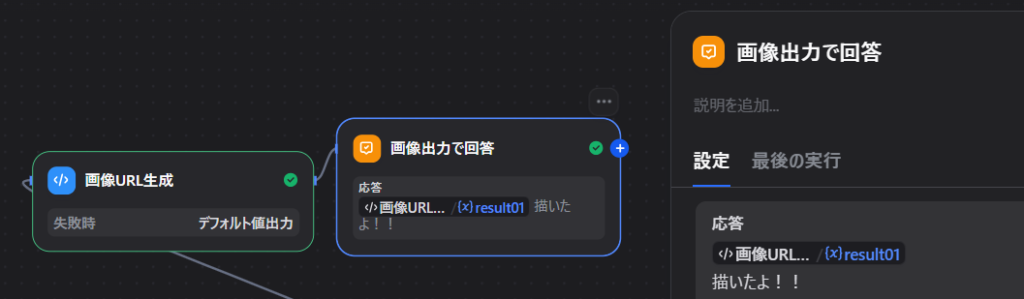
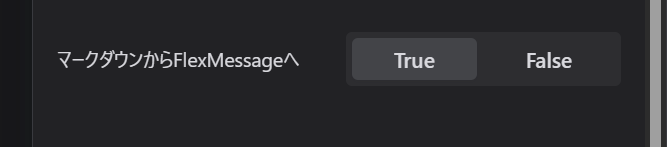
ノード設定はこんな感じです。
※プラグインのオプションをTrueにすると動作します。
画像認識させる
基本設定
LINEで画像を送ったらそれに対して反応させることができます。
まず、アプリのAPIシークレットキーを取得します。
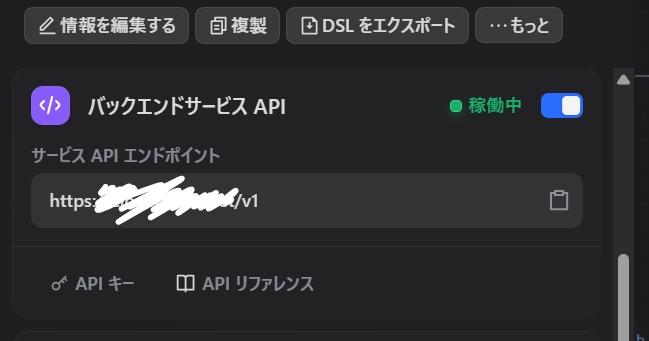
APIキーというところをクリックすると取れます。
で、このキーをプラグインのキー入力欄に貼り付けます。
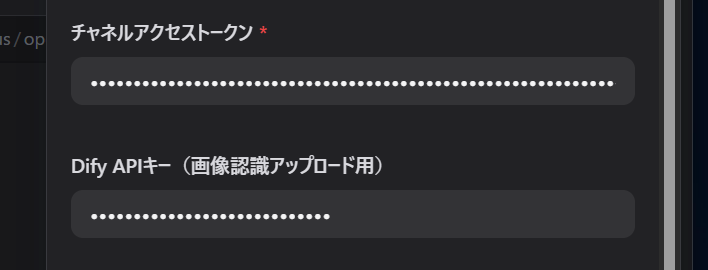
続いて、イメージ変数とプロンプトを設定します。
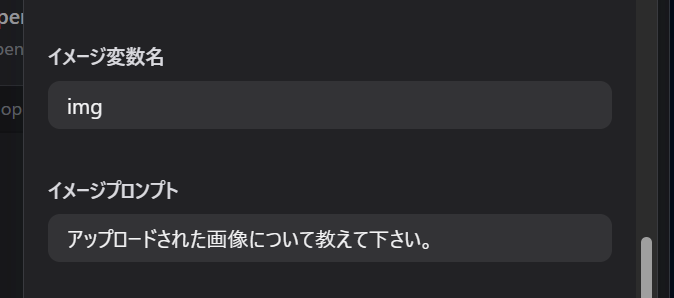
変数名は何でもいいですがデフォルトのimg、イメージプロンプトは「アップロードされた画像について教えて下さい。」とします。
開始地点の入力ノードにimg変数を追加します。
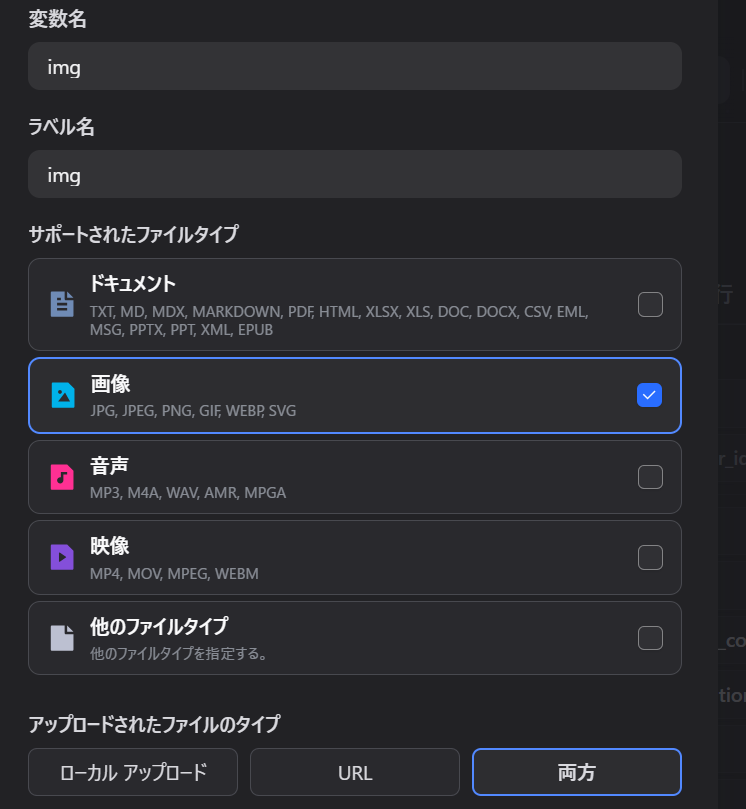
変数名=img、ラベル名=img
タイプは画像
ファイルタイプは両方
アップロード最大数は1
必須=OFF
最後に、LLMノードでビジョンをONにします。
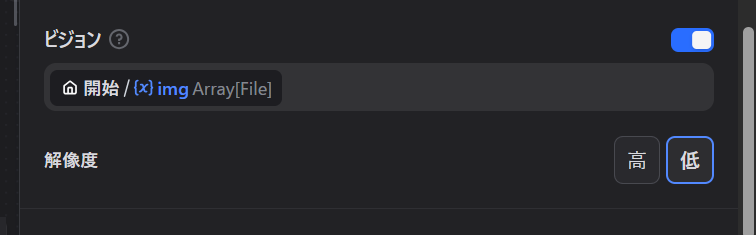
これで、LINEで画像が送信されたときその画像に対してのコメントを得ることができます。

※LINEオフィシャルアカウントマネージャの画像受取設定をONにしてないと画像が送れないので注意
待機メッセージを送る
これまでの実装だと、
ユーザ:花の絵を描いて
(応答待ち)
LINEボット:[絵] 描けたよ!!
こんなやりとりになります。
でも本当は↓にしたいですよね。
ユーザ:花の絵を描いて
LINEボット:分かった!ちょっとまってね!!
(応答待ち)
LINEボット:[絵] 描けたよ!!
LINE連携だと、全てのノード処理が終わったらいっぺんに出力が返ってきます。
待機メッセージ出力ノード→画像生成→最終メッセージ出力ノード
としても↓になります。
ユーザ:花の絵を描いて
(応答待ち)
LINEボット:分かった!ちょっとまってね!!
LINEボット:[絵] 描けたよ!!
これですが、HTTPリクエストノードで直接LINEのAPIを叩くことで実現可能です。
ブロックを追加>ツール>HTTPリクエスト のところにあります。
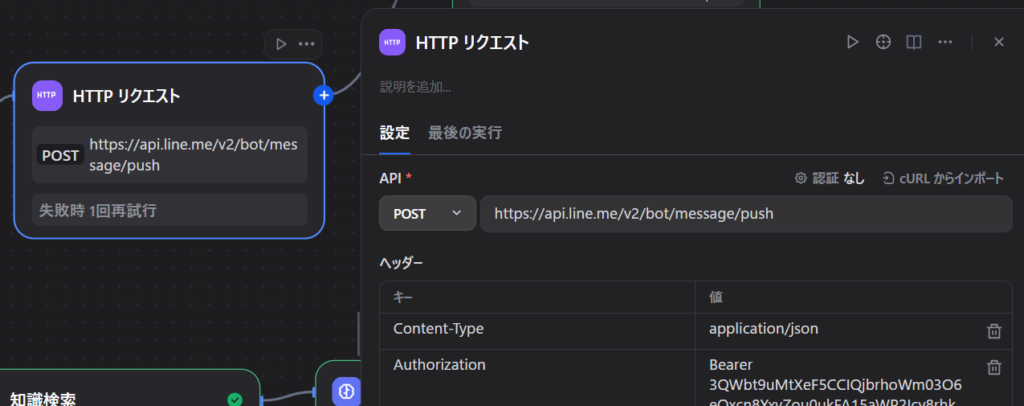
設定は以下の通りにします。
太字は各自で変更する値です。
API:POST
URL:https://api.line.me/v2/bot/message/push
ヘッダー
Content-Type:application/json
Authorization:Bearer チャネルアクセストークン
ボディ:JSON
{ "to": "入力ノードのuser_id変数",
"messages":[{
"type":"text",
"text":"分かった!ちょっとまってね!!"
}]}
うまく送れない場合はDifyのログにメッセージが出てると思うのでそれを見て下さい。
例えばチャネルアクセストークンが違ってるとこんなメッセージが出ます。
{
"status_code": 401,
"body": "",
"headers": {
"server": "legy",
"cache-control": "no-cache, no-store, max-age=0, must-revalidate",
"content-type": "application/json",
"date": "xxxxxxxxxxxxxx",
"expires": "0",
"pragma": "no-cache",
"www-authenticate": "Bearer error=\"invalid_token\", error_description=\"invalid token\"",
"x-content-type-options": "nosniff",
"x-frame-options": "DENY",
"x-line-request-id": "xxxxxxxxxxxxxxxx",
"x-xss-protection": "1; mode=block",
"content-length": "104"
},
"files": []
}その他
エラーハンドリング
例えばLLMノードで内部エラーが発生して出力できなくなったときに、エラーメッセージを出力する機構です。
面倒なのでしてませんが、ホントはやったほうがいいと思います。
やり方は簡単です。
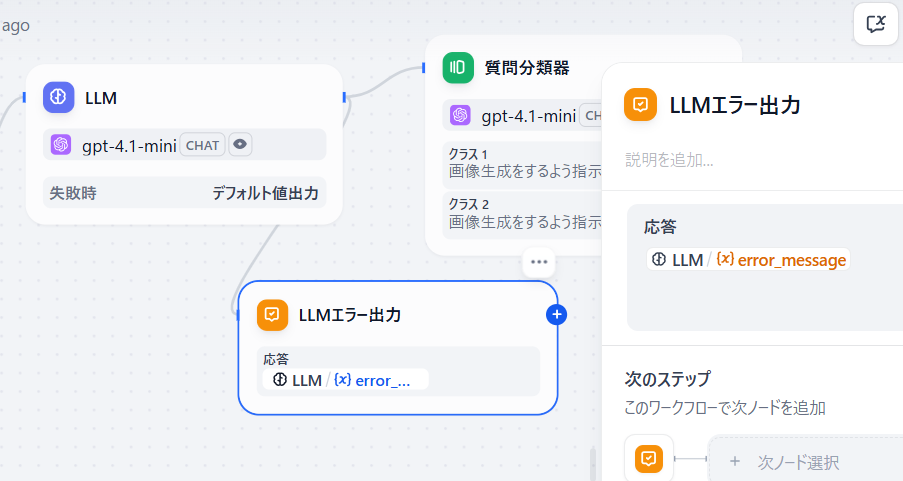
画像を見たほうが早いですが説明しときます。
例えばLLMノードなら、例外処理をデフォルト値にしてtextのとこにメッセージを入れます。
これだけだとメッセージとして出力されないので、LLMノード直後に回答ノードを接続してerror_messageを応答に設定します。
こうすると、LLMノードでコケたときにtextで設定したメッセージを出してくれるのでユーザからすると優しいと思います。
特に、キャラクターっぽいエラーメッセージを出すと楽しいですね。
例:「ごめんね、エラーが起きたみたい💦」
さいごに
Difyは神。
コメント