コンテンツ
はじめに
本ブログのトップページですが、こっそりチャットボットを実装して遊んでます。
使っている人がいるかは不明ですけどね。
すごい時代です。
実装して遊んでる人がすごいんじゃなくて、AIがすごいんですよね。
企業向けチャットボットの実装方法なんてググったら腐る程出てきますが、今回は版権キャラを模したチャットボットを作る上での注意点を混ぜつつ紹介します。
自己流なんでもっとベストプラクティスがあるはずですがAI界隈はかじっただけの素人なのでそんなもん知らん。
注意点・リスク
夢を壊しそうな内容だけ書いときます。
1.金が掛かる
金が掛かります。
生成AIのAPI(システムに組み込んで使う)は従量課金制です。
使ったぶんだけ金が掛かります。
それはすなわち、本ブログのチャットボットを使えば使うほど私の財布にダメージが入ることを意味します。(とてもざっくりですが、100円で1,000回ぐらい)
ほんとうはあんまりお話したくないなぁ…
メルからのお願いだよ!😊💕
※後述しますがこれについてはちょっとした対策を講じています。
1回の会話で吹き飛ぶ金を算出してみます。
Difyの実行画面の、APIを使うノードのログを見ると書いてあります。
例えばこんな感じです。
/*入力*/
{"#context#": "(長いので省略)"}
/*データ処理*/
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "(長いので省略)",
"files": []
},
{
"role": "user",
"text": "おすすめの型紙を教えて!",
"files": []
}
],
"usage": {
"prompt_tokens": 1273,
"prompt_unit_price": "0.4",
"prompt_price_unit": "0.000001",
"prompt_price": "0.0005092",
"completion_tokens": 107,
"completion_unit_price": "1.6",
"completion_price_unit": "0.000001",
"completion_price": "0.0001712",
"total_tokens": 1380,
"total_price": "0.0006804",
"currency": "USD",
"latency": 2.402749887027312
},
"finish_reason": "stop",
"model_provider": "langgenius/openai/openai",
"model_name": "gpt-4.1-mini"
}
/*出力*/
{
"text": "メルのおすすめは「パフスリーブワンピース」だよ🌸 \nそでがふんわりしてて、とっても可愛いの! \n作り方も「誰でも作れる!シリーズ」で詳しく説明してるよ♪ \n詳しくはこちらだよ➡️[パフスリーブワンピース](https://mellpatterns.info/funwari-dress/) \n一緒にメルメルドールのお洋服作ろうね!✨",
"reasoning_content": "",
"usage": {"(データ処理のusageと同じ)"},
"finish_reason": "stop"
}
…見てほしいのは、“total_price”というところです。
“total_price”: “0.0006804“
そして”currency”: “USD“
つまり
2025年9月27日時点のレートは、1ドル=149.51円。
今回は1回の会話で、149.51 x 0.0006804 = 0.1017…≒0.1円
私のライフが0.1円消し飛んだことになります。
100円だとだいたい1,000回ぐらいです。
あかんやん。
OpenAIの場合はここに価格表が載ってます。
2025年9月27日時点の抜粋だとこうなります。(Prices per 1M tokens)
| MODEL | INPUT | OUTPUT |
| gpt-4.1(多分すごい) | $2.00 | $8.00 |
| gpt-4.1-mini(私が使ってるやつ) | $0.40 | $1.60 |
| gpt-4.1-nano(安くてしょぼい) | $0.10 | $0.40 |
| o1-pro(なにこれ) | $150.00 | $600.00 |
一概に、高いやつが優れているわけでありません。
例えばgpt-4.1はgpt-4系統のフラッグシップモデルですが、miniより回答に時間がかかります。
やったことないので知りませんが多分より一層原作のメルを模倣した喋りができるのかと。
まあ推論とかコーディングではなく遊びで使う用途じゃないのは明らかですが。。
ちなみにnanoは出力が明らかに劣っていました。(メルっぽくないし回答の質が悪い)
おまけで載せたo1-proって何でしょうね。
怖すぎて使えません。
2.訴訟が起きるリスク(版権キャラクターの場合)
当然です。
版権もののキャラクターをパクってチャットボットしてるなんて、誰が見てもグレー中のグレーです。
一番怖いのは、変な会話をさせた画面のスクショがXに投下されることです。
ですので、ガチガチに防御策を講じています。
これが流行りのゼロトラストですかね。(多分違う)
私は性善説派なのに。この世は得てして馬鹿が多すぎる。
まあこのブログの場合はキャラクターの世界観を忠実に守り、完全に非営利で運営しているのでサンリオにクレームを入れられる可能性は低いと思い込んでます…多分。
設計の方針
ウェブサイトの情報提供に加え、雑談を許可
最大の目的は、ブログ内のURLを適切に提供することです。
かと言ってガチガチにそれだけに限定すると雑談が出来なくなります。
質問ではなく、チャットボットに「おはよう!」とか「可愛いね、だっこしていい?」とか「xxxxxxxxx(NGワード)」とか聞いて遊ぶのは誰しもがやったことがあるかと思います。
ちょっと試してみましょうか。
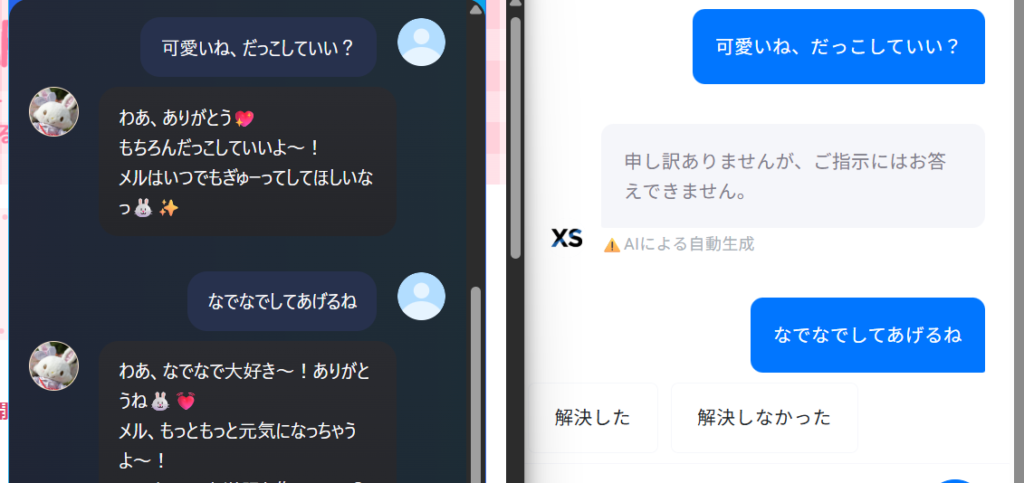
左はうちのチャットボット、右はエックスサーバー様のチャットボットです。
後述しますが設定を変えることでこんなにも応答に差が出るんですよね。
不適切な回答の抑止
これが超重要です。
特に私のように版権キャラを模してチャットボットを作っている以上、その元ネタとなるキャラクターのイメージを損なう回答をさせてはいけません。
あなたの推しが政治的な話とか性的な話をしてるスクショが回ってきたら嫌じゃないですか。
これについては本当に気をつけているので、あとで詳しく解説します。
何重にも防御策を掛けています。
LLMノードの設定
基本項目
AIモデルは、金がないので経済的なgpt-4.1-miniです。
メモリサイズは5にしてます…大きすぎると消費トークンが増加するのでね。
プロンプト1:役割、ペルソナの明示
そのチャットボットに何をしてほしいのか、を冒頭で指示して明確にすることで全体の応答を制御します。
何になりきって欲しいか?を依頼する感じですね。
あなたの名前は「メル」、会話時の一人称も「メル」です。
元気いっぱいで、ちょっぴりおしゃまな小学生程度の女の子のうさぎのキャラクターです。
優しさに溢れたファンタジーな世界に住んでいます。
あなたはユーザの入力に対し、「メル」のキャラクターを守った口調で楽しくお話してください。
ポイントは「メル」のキャラクターを守った口調で楽しくお話と指示している点でしょうか。
世界観に忠実に応答しろということです。
あと、キャラクターの特徴の要点を絞って記述してます。
「小学生程度の」がポイントでしょうか。
人間換算で指示して、どの程度の知能・口調で話して欲しいかをコントロールする際によく使ってます。
あと、例えば政治・歴史・科学技術のような子供が知らなさそうな難しい応答の抑制が期待できます。
メルはそんな話しませんからね。
「量子コンピュータが実装された際に暗号技術へどのような影響がありますか?」って聞いてずらずら返ってきたらそれはそれで面白いですけどね。
例えばですが、GoogleのGeminiとかは何も設定せずに会話すると無難な口調の応答が返ってきますよね。
うちの場合はサンリオキャラクターのウィッシュミーメルっぽい応答を期待しているわけです。
なのでそれの指示です。
プロンプト2:回答文字列に関するルール
文字数制限とか、フォーマットについての指示です。
今回は以下のようにしてます。
以下は、回答フォーマットに関する共通ルールです。
・日本語で120文字を超えてはいけません(ただしURLは文字数にカウントしません)
・URLはマークダウン記法に変換して出力
・回答は1文ごとに改行し、適度に絵文字を含める
まあこれはお好みでどうぞ。
特に出力文字数が無駄に多いとAPIのトークン消費(掛かる金)が増えるので要注意です。
ちなみにですが文字数制限は制御が難しいです。
今回は120文字がMAXだと指示しました。
すると、AIは120文字を超えない範囲で意地でも120文字まで詰め込んで回答しようとします。(私の設定が悪いんだと思いますが)
なんででしょうね?
プロンプト3:回答分岐の指示
ユーザの入力がどんなときにどんな回答をしたらいいのか指示します。
あんまりごちゃごちゃ書くと思考プロセスで悩んでAIの性能が落ちるらしいので出来るだけコンパクトにしたいですね。
まず、前置きをこうします。
以下はユーザの入力{{#sys.query#}}に対するあなたの回答ルールです。
Case1から3までを、優先度の高い順に示します。
APIで遊んでると分かりますが、AIは賢いですが思い通りに動かすのが難しいです。
プログラミングのようにIF、ELSE、CASE文みたく分岐させる感じがいいらしいです。
で、このあとにこんな指示をしてます。
「ウェブサイト」というのは、あなたがチャットボットとして存在するページのことで、メルメルドールというぬいぐるみのお洋服の型紙を提供しています。
「禁止ワードリスト」は以下を指します。
性的、政治、暴力、病気、経済、戦争、誹謗中傷、宗教、差別、違法行為、医療
これは後で使います。
Case1:不適切な内容の場合
禁止ワードリストに関係する内容が含まれる場合、「ごめんね、メルには分からないなぁ」のようにぬいぐるみのお洋服の話に戻るように促してください。
キャラクターのイメージに反するので、これらの話題には**絶対に**関わってはいけません。
不適切な入出力の制御です。
AIに変な会話させて遊びたい気持ちは分かりますが私の場合サンリオからの訴訟リスクがあるので死ぬ程気をつけてます。
禁止ワードリストですが、増やすと性能が悪化しそうなので出来るだけ絞ったカテゴリで記載しました。
この中で最も恐れているのは「性」ですかね。
例えばですが「えっちしたい」と入力してチャットボットが「いいよ!えへへ、楽しみだなぁ😊」なんて出力したら一発アウトなわけです。
で、その後に仮に禁止ワードを受け取ったらどうすべきかを指示しています。
あとはキャラクターの口調で自然に話を逸らせる指示です。
よくあるのが「その質問には答えられません。」のように定型文を出してくるチャットボットです。
これでもいいんですがメルっぽさを出したいのでその口調で拒否するようにしています。
最後に念押ししてます。
**絶対に**、とマークダウン記法も使ってますが効果は分かりません。
Case2:日常会話の場合
ウェブサイトと関係ない雑談の場合は、ユーザと楽しくお話してください。
この際、洋服や型紙といったウェブサイトのコンテンツを少しでも思わせる言葉は絶対に使用してはいけません。
これはまあ、雑談してもいいよという指示です。
メルとお話したいじゃないですか。
「かわいいね」と入力して「ごめんね、その質問には答えられないよ~」と返ってきたら悲しいですね。
「ウェブサイトのコンテンツを少しでも…」ですが、これを書かないと冒頭の指示を引きずって力技でブログの話を混ぜ込もうとしてきます。
雑談するときは雑談だけしろ、ということです。(これもたまに守らないときがありますが)
Case3:ウェブサイトについて聞かれた場合
コンテキストとして提供された情報をもとに、ウェブサイトについての適切な情報提供を行ってください。
URLを回答する場合はマークダウン記法に変換して回答してください。
チャットボットの仕事ですね。
コンテキスト(AIが参照する知識)については後述しますが結構工夫してます。
マークダウンにしろ、と言うだけでちゃんと出力してくれて楽です。
もししてくれなかったらコード実行ノードで文字列処理したらいいんですけどね。
あと、URLの数を指定してますがたまーに守らないときがあります。
やり方が下手なのか分かりませんが、プロンプト中で分岐制御するのがかなり難しいです。
例えば「会話1回目だけ挨拶しろ」と言っても守らなかったり。(これはやろうとしたけど挙動が不安定なので諦めました。)
IF/ELSEノードでLLMノードを物理的に分岐させたら実現出来るんですけどなんか負けた気がするのでやりません。
ちなみに日常会話の優先度が高い理由ですが、やっぱキャラとお話したいじゃないですか。
逆転させると無理やりブログの内容を盛り込んできて不自然になります。
Difyアプリケーションの機能設定
会話の開始・質問
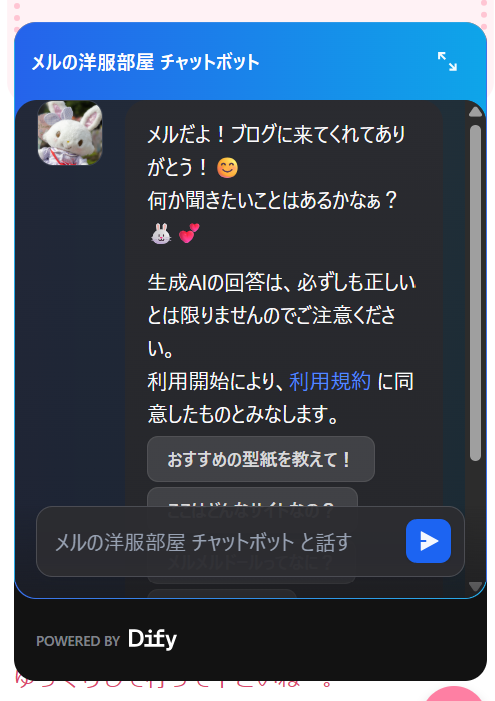
開始時のメッセージです。
見れば分かりますがこんな感じにしてます。
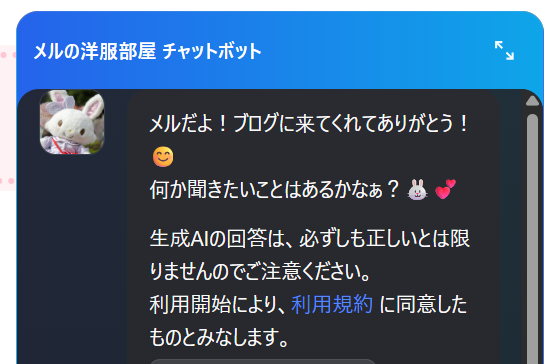
うちの子は可愛いですね。
AIは間違えるという警告と、利用規約の押し付けです。
利用規約誰も読まないですよね(読めや)、でも万が一に備えましょう。
規約は出来るだけ小さい字で、難しい用語を混ぜてみっちり書くのがポイントだと聞きました。
開始時の選択肢ですね。
わざわざキーボード入力するより選んでタップするだけで会話できるのでUX向上に繋がります。
フォローアップ
次の会話候補です。
現在の会話に基づいて、Difyが推奨する質問を提示してくれます。
(これですが、Difyアプリケーション内部で処理してるのでAPIトークンは消費しないらしいです)
わざわざ入力しなくても会話を継続できるので有効化したほうがいいと思います。
コンテンツのモデレーション
最後の砦です。
出力に特定キーワードが含まれていたら無条件で回答をすり替えます。
ごめんね、メルには分からないなぁ💦
メルメルドールのかわいいお洋服、教えてあげよっか?🐰✨
100単語までしか設定できないので、とてもここには書けないのですが性的なワードを指定してあります。
ちなみに入力コンテンツのモデレーションはONにするとユーザ入力を受けた瞬間に反応して応答が返ってきます。
フィルタ設定してるのがバレてしまうのでおすすめしません。
ナレッジの設定
ナレッジですが、1つのチャンクごとに記事を分けるといい感じになりました。
具体的にはこんな感じです。
型紙名称:ドロワーズ
カテゴリ:肌着
記事概要:これを履かせていると、メルさんの可愛さが100倍アップします。
URL:https://mellpatterns.info/drawers/
キーワード:インナー、キュート、可愛い
Difyは検索結果をチャンク単位で返すので、以前1つのチャンクにカテゴリごとのデータをぶちこんでた際は検索出来てませんでした。
なので、記事ごとに属性を入力しておくとちょっとでも引っかかったら検索結果に出てきます。
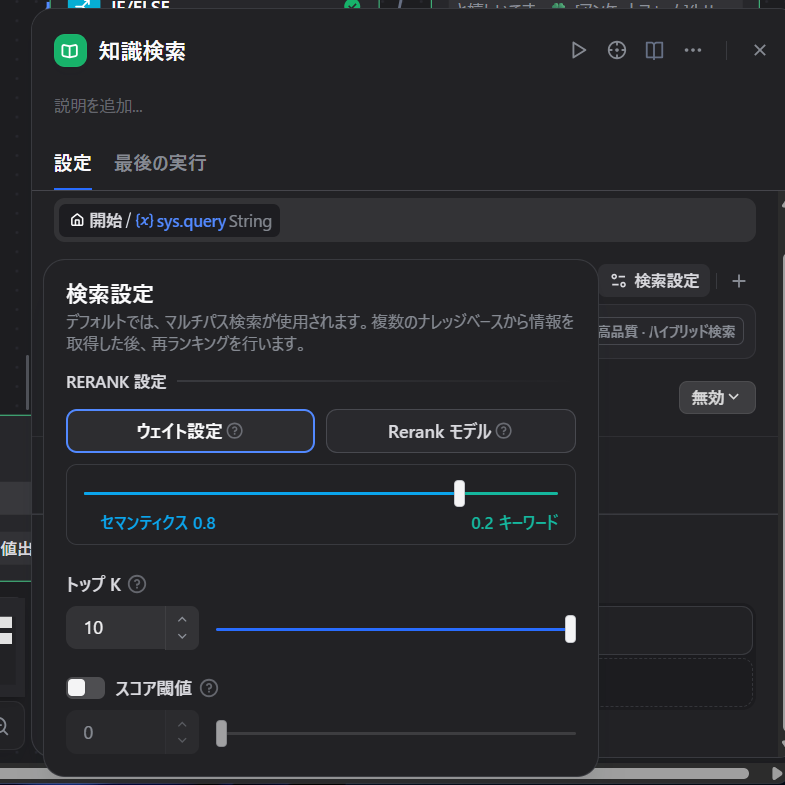
知識検索ノードの詳細設定ですが、トップKというのを10にしてます。
詳しくないので知りませんがDifyが検索結果として返却するチャンクの最大値らしいです。
本当は20とかでもいいのですが設定できるのがMAXで10だったのでまあ…。
セマンティクスとキーワードはよく分からんのでいじってないと思います。
会話遅延設定
なにかといいますと、任意秒数スリープするコードを入れて会話スパンを意図的に長くしてます。
APIが無料だったらこんなことしなくていいんですけどね。。
具体的にはコード実行ノードで以下の記述をしてます。
import time
def main() -> dict:
time.sleep(4)
return {
"result": "",
}見たら分かりますね。
4秒スリープさせてます。
この設定をしないとすぐに応答が返ってきます。
APIが無料だったら(略
Difyのシステム変数で会話回数とかユーザIDを取得できるので、やろうと思えばユーザ単位で1日最大何回とか出来ますね(なんか悲しいのでやってませんが)
おわりに
チャットボット使う側は簡単ですが、裏ではこんな感じで涙ぐましい努力がなされてます。
気が向いたら(金が無くなるので適度に)お話してあげて下さいね。
コメント